Freelancer Engagement
Project No. 1155
A common repository of Indian Language Data for the promotion and creation of language resources for the Human Language Technology
Under BHASHINI, Funded by MeitY, Govt. of India

The Mission Bhashini, an initiative by the Ministry of Electronics and Information Technology (MeitY), Government of India, has recently recognized and funded the establishment of the "COIL-D: Centre of Indian Language Data." This esteemed project is being led by Prof. Asif Ekbal, Associate Professor at IIT Patna, in collaboration with IIT Delhi, IIIT Delhi, IIT Guwahati, IGDTUW, MIT Manipal, and DIBD.
Create language resources like parallel corpora for MT between Indian languages, as well as benchmark datasets for PoS tagging, NER, ASR, and TTS
Curate core Hindi data from science, healthcare, agriculture, climate, tourism, judiciary, education, governance & conversational content
To create, preserve, and standardize language resources to support NLP research and applications
This dataset will power Hindi-to-21 language translation and multilingual chatbots, enabling efficient cross-sector communication
Establish a central repository for Indian language data and provide a platform for developing and benchmarking HLT applications
With minimal post-editing, you can quickly translate large volumes of text, making it ready for publication on print and digital platforms
Develop leaderboards to evaluate MT, PoS tagging, NER, NLG, sentiment analysis, ASR, and TTS, ensuring systematic NLP assessment
From these advanced tools at no cost surpassing existing solutions like Google Translate, while also enriching our linguistic heritage
As a data partner, your organization will be acknowledged on the MeitY portal for its valuable contributions to this important national project. Upon completion, due credit will be given for your support, highlighting your role in this significant initiative.







The COIL-D (Centre of Indian Language Data) project aims to establish a unified repository of Indian language data and create a platform for systematic evaluation of Machine Translation (MT) and other Natural Language Processing (NLP) systems. It promotes the creation and preservation of language resources for Human Language Technology (HLT) applications and defines standards for linguistic benchmarking.
Identify and list existing Hindi datasets and tools. This helps understand current resource availability.
Collect data from key domains like health, education, and governance. It ensures coverage of real-world language use.
Develop new data for Machine Translation and NLP. Set benchmarks to evaluate tool performance.
Create leaderboards to assess translation systems. They help track progress and encourage improvements.
Develop scoreboards to evaluate speech recognition and synthesis systems. These track accuracy, clarity, and performance.
Define evaluation tests for tools like PoS and NER taggers. This ensures fair and consistent evaluation.
The primary motivation behind gathering Hindi language data is to facilitate translation into 17 other Indian languages. Additionally, we are focusing on Tamil-to-Dravidian language translations.
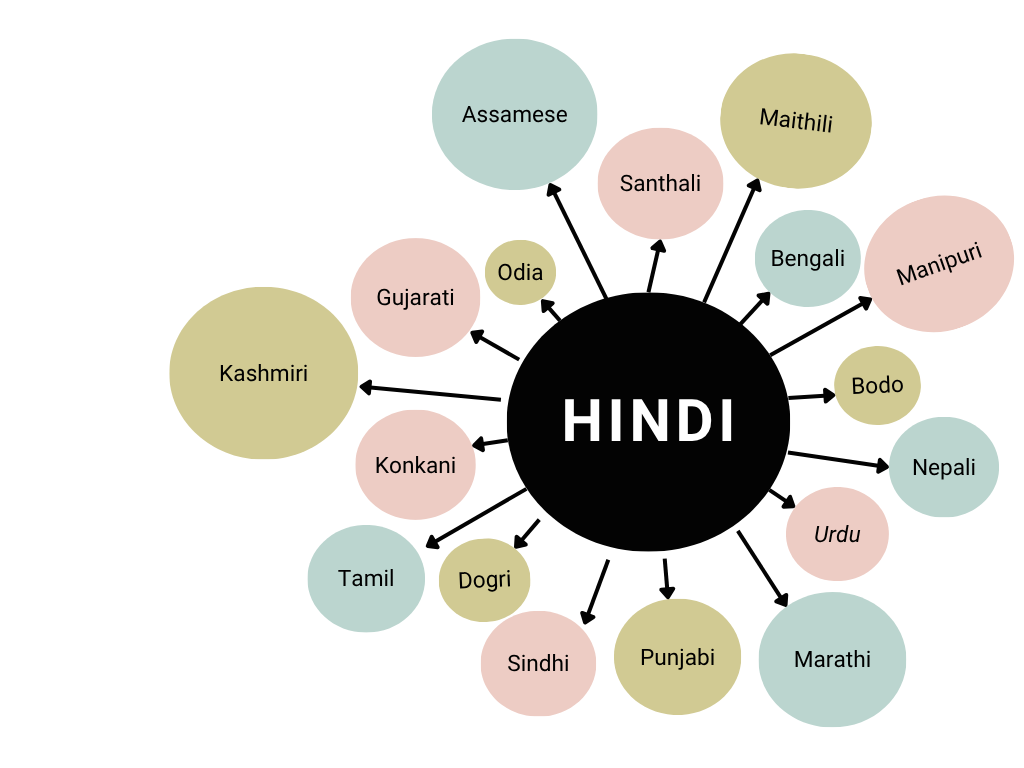
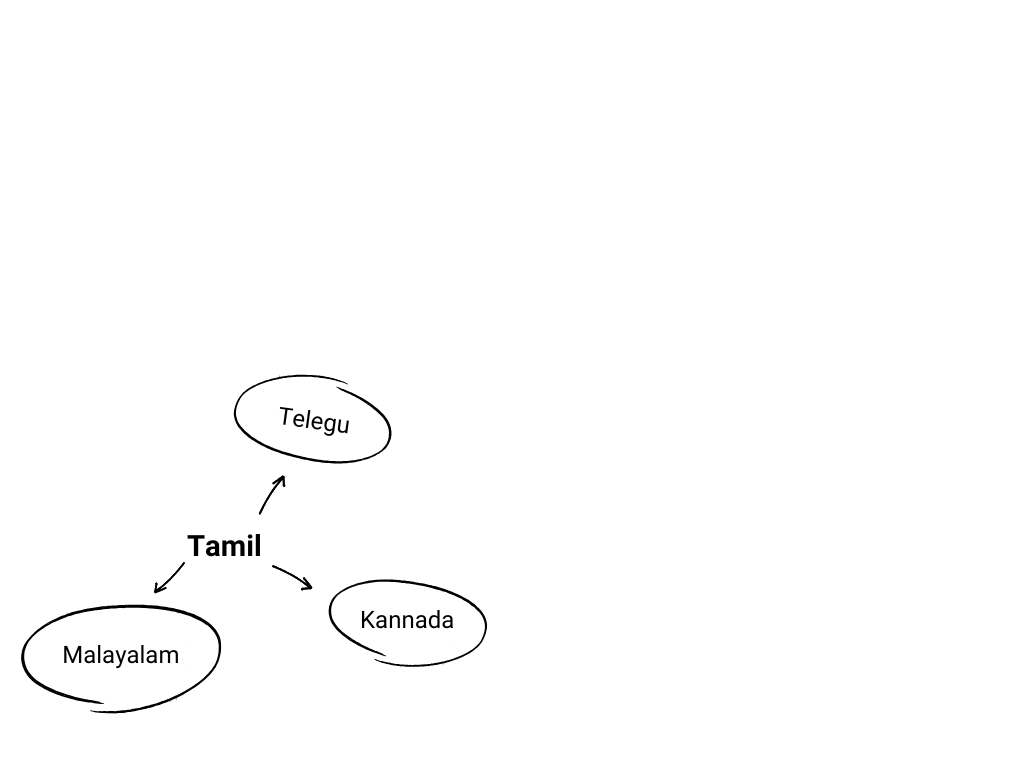
A significant emphasis is placed on the creation of high-quality language resources. Efforts will be made to generate parallel corpora, aiming for 50k–100k sentence pairs for each language pair, with 2k additional sentence pairs for evaluation purposes. Hindi will serve as a central language, enabling efficient translation between Hindi and other Indian languages. Furthermore, the creation of leaderboards for MT, ASR, and TTS will provide standardized platforms for performance benchmarking. We will also establish benchmarks for various linguistic tools, such as PoS taggers, Named Entity Recognition (NER) systems, Natural Language Generation (NLG), and Sentiment Analysis tools, which will enhance resources available for Indian languages.



A leaderboard is a platform or framework used to benchmark and compare the performance of different models and algorithms on specific natural language processing tasks. In this case, the leaderboard compares the performance of Machine Translation systems for Indian Languages. The users of this system can be classified broadly into admin, developers and viewers. The admin side will maintain the leaderboard, updating it with new benchmarking datsets, adding newer tasks and other features to the existing framework. The developers are users who would want to compare their MT hypothesis again state of the art model hypothesis. Lastly, the viewers are the visitors to the website.


Principal Investigator
Associate Professor
Computer Science and Engineering
IIT Patna, India

Assistant Professor
HSS
IIT Delhi, India

Associate Professor
Electrical Engineering
IIT Delhi, India

Associate Professor
Computer Science and Engineering
IIT Guwahati, India

Assistant Professor
Computer Science and Engineering
IIIT Delhi, India

Professor
AI & Data Science
IGDTUW, India


Assistant Professor (Senior)
Manipal Institute of Technology, MAHE
Manipal, India

Domain: Education

Domain: Media & Broadcast

Domain: Various

Domain: Agriculture

Domain: Various

Domain: Various

Domain: Various

Domain: Science & Technology

Domain: Various

Domain: Various

Domain: Tourism

Domain: Judiciary

Domain: Governance & Policies

Domain: Various

Domain: Tourism

Domain: Healthcare

Domain: Science & Technology

Domain: Science & Technology

Domain: Climate

Domain: Climate

Domain: Climate

Domain: Governance & Policies

Domain: Governance & Policies

Domain: Governance & Policies

Domain: Governance & Policies
Temporary positions available on the COIL-D project (sponsored by MeitY). Applicants should send resume (PDF) and required documents to the email provided below.
IIT Patna, Bihta Kanpa Rd, Patna,
Dayalpur Daulatpur, Bihar 801106
+91 6115 233 338
coild.bhashini@gmail.com